
SORA 보다 더 미친 생성AI 'EMO'
EMO: Emote Portrait Alive
알리바바에서 만든 진짜 '미친' AI 영상 생성 모델이 나왔다.
이름은 EMO라고 하는데 인물의 이미지와 오디오를 함께 입력하면 오디오에 맞춰 말하거나 노래하는 영상을 생성해주는 생성형 AI이다.
보란듯이 소라의 데모 영상의 한 장면을 캡쳐해서 립싱크까지 생성했다.
페이셜 에니메이션은 거의 사람과 큰 차이가 없다.
소라 퀄리티의 영상에다가 + EMO 퀄리티의 보이스 입히는 기술이 합쳐진 것이라고 할 수 있겠다.
조금 무섭기도 하고, 충격적이다.
포스팅 하단에 샘플영상들이 있는데 다소 충격적이다.
솔직히 진짜라고 해도 누가 의심을 할 수 있을까 싶다.

알리바바그룹 지능형 컴퓨팅 연구소가 말하기를...
우리는 표현력이 풍부한 오디오 중심의 세로-비디오 생성 프레임워크인 EMO를 제안했습니다. 단일 참조 이미지와 음성 오디오(예: 말하기 및 노래)를 입력하면 우리의 방법은 표정이 풍부한 음성 아바타 비디오와 다양한 머리 자세를 생성할 수 있으며, 동시에 입력 비디오의 길이에 따라 지속 시간에 관계없이 비디오를 생성할 수 있습니다.
알리바바그룹 지능형 컴퓨팅 연구소가 말하기를...
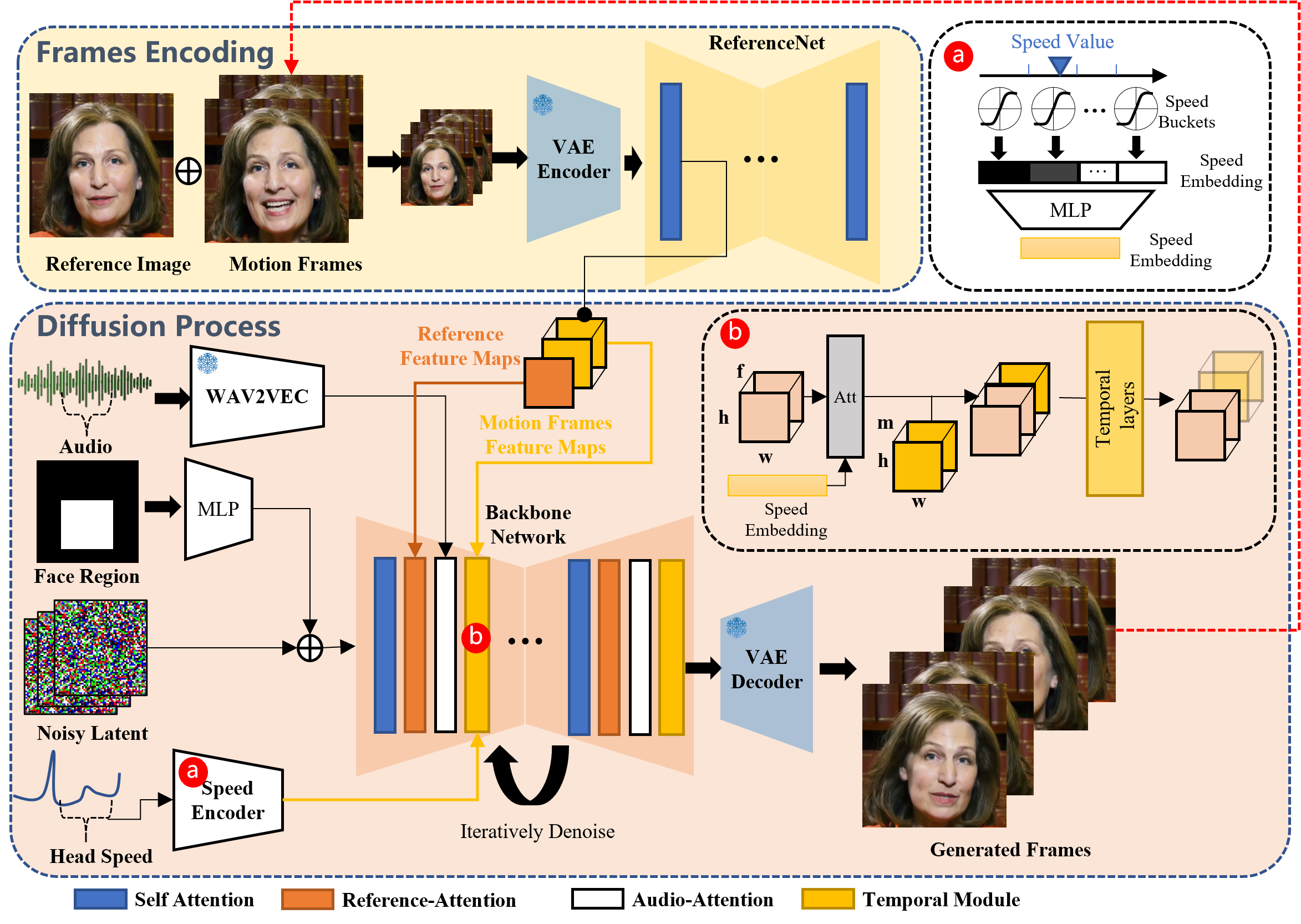
우리의 프레임워크는 크게 두 단계로 구성됩니다.
1. 프레임 인코딩이라고 하는 초기 단계에서 ReferenceNet은 참조 이미지와 모션 프레임에서 특징을 추출하기 위해 배포됩니다.
2. 이후 확산 프로세스 단계에서는 사전 훈련된 오디오 인코더가 오디오 임베딩을 처리합니다.
얼굴 영역 마스크는 다중 프레임 노이즈와 통합되어 얼굴 이미지 생성을 제어합니다. 그 다음에는 잡음 제거 작업을 용이하게 하기 위해 백본 네트워크를 사용합니다. 백본 네트워크 내에서는 Reference-Attention과 Audio-Attention이라는 두 가지 형태의 Attention 메커니즘이 적용됩니다. 이러한 메커니즘은 각각 캐릭터의 정체성을 보존하고 캐릭터의 움직임을 조절하는 데 필수적입니다. 또한 시간 모듈은 시간 차원을 조작하고 동작 속도를 조정하는 데 활용됩니다.
EMO의 샘플들
레퍼런스 이미지와 모션 특징을 추출후 생성된 오른쪽을 감안해서 감상하도록 하자..
초상화를 노래하게 만드세요
다양한 캐릭터와 대화하기
다양한 언어 및 초상화 스타일
-제니 - SOLO로 생성된 AI 소녀. (한국어)
-장국영으로 생성된 AI (광둥어)
-인터넷 chillout 자료로 생성된 AI 소녀 (북경어)
-AnyLora의 AI 이미지로 생성 (일본어)
-AI 모나리자로 생성
-오드리햅번으로 생성한 AI
-KUN KUN으로 생성한 초고속 립싱크 테스트
-더 조커의 소스와 다크나이트의 사운드 결합

오픈 AI '소라(Sora)' 출시 (소라 사용 방법)
오픈 AI '소라(Sora)' 사용 방법 소라는 텍스트를 비디오로 변환할 수 있는 AI 모델으로 명령어를 입력하면 최대 1분 분량의 영상을 만들어냅니다. 오픈 AI(OpenAI)의 새 인공지능 모델 ‘소라’(Sora)
web3.memebro.kr
AI 반도체 시장이 10배 더 커진다
엔비디아가 시장 80% 장악 AI 시장, 10배 더 커진다 엔비디아는 2023년 4분기 매출이 전년 동기 대비 265% 늘어난 221억달러를 기록했다고 밝혔다. 영업이익은 136억1500만달러로 전년 동기(12억5700만 달
web3.memebro.kr
아직 토큰이 없는 AI 프로젝트들
2024년의 가장 큰 기술의 화두 AI 반도체 기술은 당연하고, 당연히 크립토의 기술이 접목될 수 밖에는 없는데 AI프로젝트와 직접적으로 연관성이 있으면서도 토큰이 발행될만한, 새로운 기회를 가
web3.memebro.kr






